|
|
|
|
|
|
Abstract
|
Motion forecasting plays a significant role in various domains (e.g., autonomous driving, human-robot interaction), which aims to predict future motion sequences given a set of history observations. However, the observed elements may be of different levels of importance. Some information may be irrelevant or even distracting to the forecasting in certain situations. To address this issue, we propose a generic motion forecasting framework (named RAIN) with dynamic key information selection and ranking based on a hybrid attention mechanism. The general framework is instantiated to handle the tasks of multi-agent trajectory prediction and human motion forecasting, respectively. In the former task, the model learns to recognize the relations between agents with a graph representation and to determine their relative significance. In the latter task, the model learns to capture the temporal proximity and dependency in long-term human motions. We also propose an effective double-stage training pipeline with an alternating training strategy to optimize the parameters in different modules of the framework. We validate the framework on both synthetic simulations and motion forecasting benchmarks in different domains, demonstrating that our method not only achieves state-of-the-art forecasting performance, but also provides interpretable and reasonable hybrid attention weights. |
||
| |
||
Key Ideas and Contributions
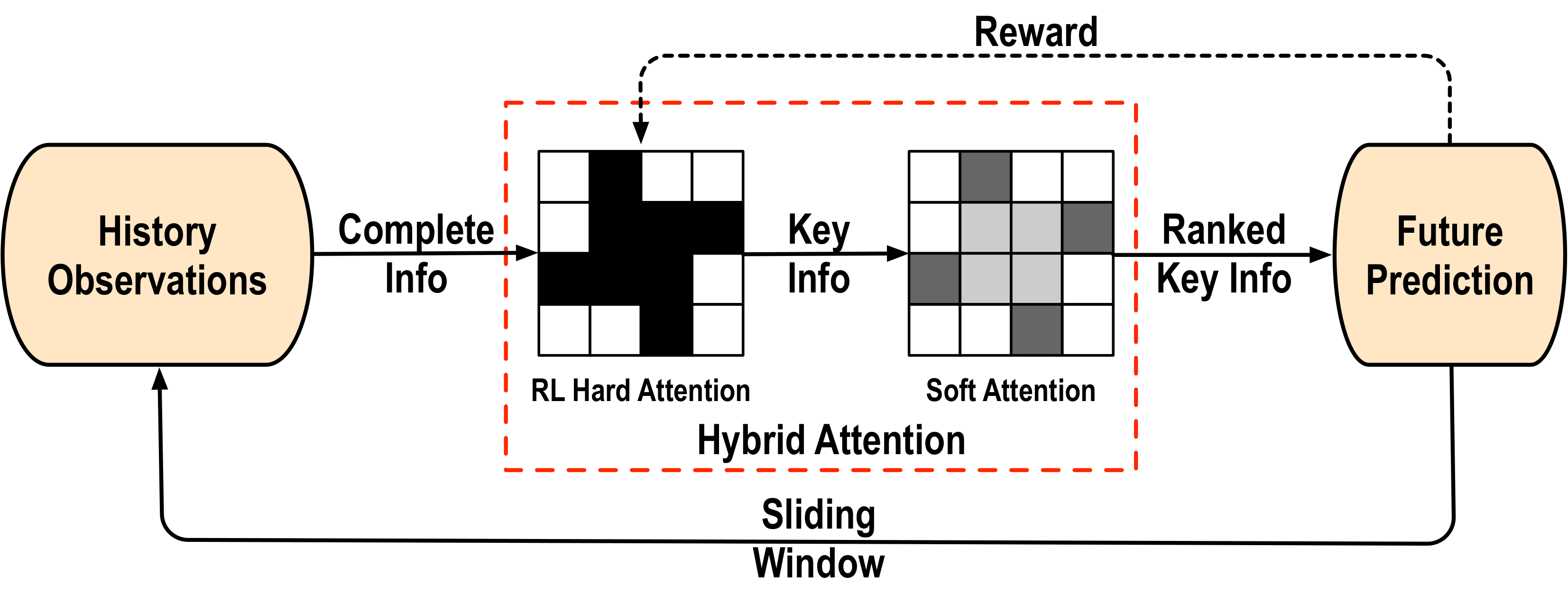 Motion Forecasting Framework: We propose a general motion forecasting framework with key information/element selection and ranking based on a novel hybrid attention mechanism. The whole procedure can be iteratively applied over time with a sliding window to enable dynamic selection of key information to adapt to evolving situations. Hybrid Attention Mechanism: The hybrid attention mechansim consists of an RL-based hard attention to discriminate key information from complete observations and a soft attention counterpart to further figure out relative significance of the key information. We propose an effective double-stage training pipeline with an alternating training strategy to improve different modules in the framework alternatively. |
||
 Multi-Agent Trajectory Forecasting: We instantiate the general framework and propose a novel graph-based model for multi-agent trajectory forecasting. The model consists of three components: graph message passing module (GMP), RL based hard attention module (RL-HA) and soft graph attention based motion generator (SGA-MG), which cooperate closely to improve the final prediction performance. More specifically, for the prediction of a certain target entity, GMP collects information from other entities across graph G. RL-HA discriminates the key relevant elements from the complete observations and provides SGA-MG with an inferred relation graph G' with only selected edges, which is a natural generalization of the traditional hard attention to graph representation. SGA-MG uses soft attention weights to rank the relative importance of key information and generates future trajectories. The prediction together with the ground truth provides rewards to RL-HA during the training phase to guide the improvement of the RL edge selector. GMP is pre-trained to collect contextual information across the whole graph. SGA-MG is pre-trained with a fully connected topology in order to improve training efficiency and stability as well as to enable informative initial reward. Human Skeleton Motion Forecasting: We also apply our method to capture long-term temporal dependency in skeleton based human motions. Instead of selecting important or relevant entities, here we propose to utilize the RL-HA module to discriminate key information over the whole history horizon. It can be either frame-wise selection or segment-wise selection. Please refer to the paper for more details about this application. |
||
| |
||
Particle Physics System
 |
||
|
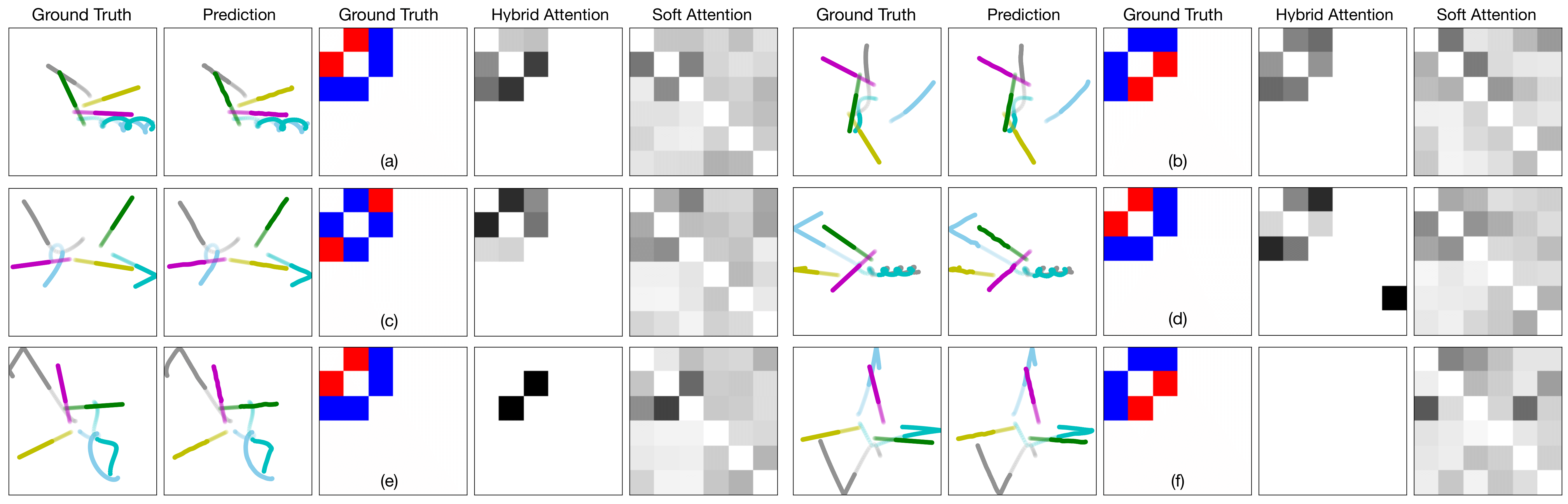
Visualization of particle trajectories and learned attention maps: The semi-transparent segments represent the observation of 30 time steps and the solid ones represent the prediction of future 50 time steps. In the ground truth relation map, red denotes "repel" and blue denotes "attract". In the attention maps, darker color indicates larger weight. Note that we do not consider self-attention (i.e., zero diagonal). Please refer to the paper for more quantitive results and discussion. |
|
||
|
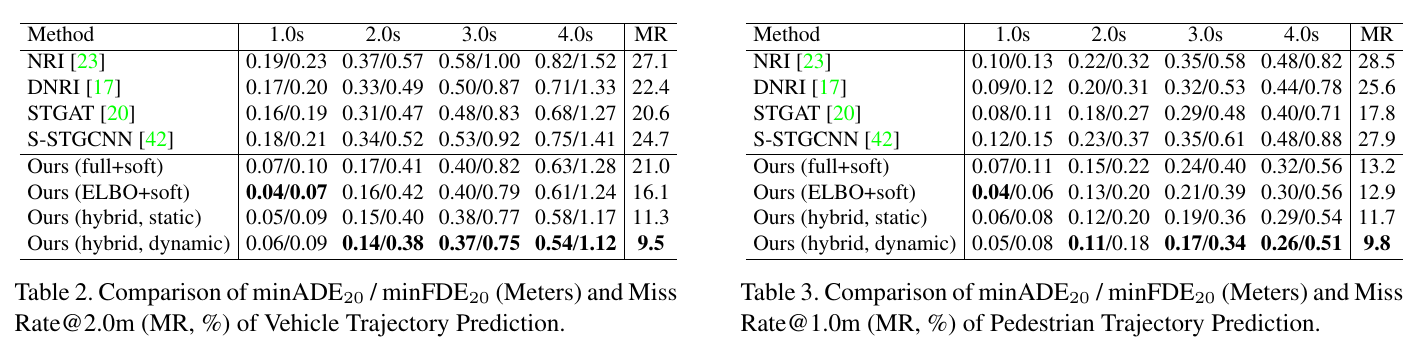
Quantitative results on nuScenes trajectory prediction benchmark: In this paper, we validated our RAIN framework on the nuScenes dataset, which handles long-term prediction of heterogeneous traffic participants (i.e., vehicles and pedestrians). We predicted the future 4.0s (20 frames) given the history observations of 2.0s (10 frames). The comparison of quantitative results is shown in Table 2 (vehicles) and Table 3 (pedestrians). The experimental results demonstrate that RAIN achieves state-of-the-art performance in terms of minADE and minFDE. Please refer to the paper for more details. |
||
|
||
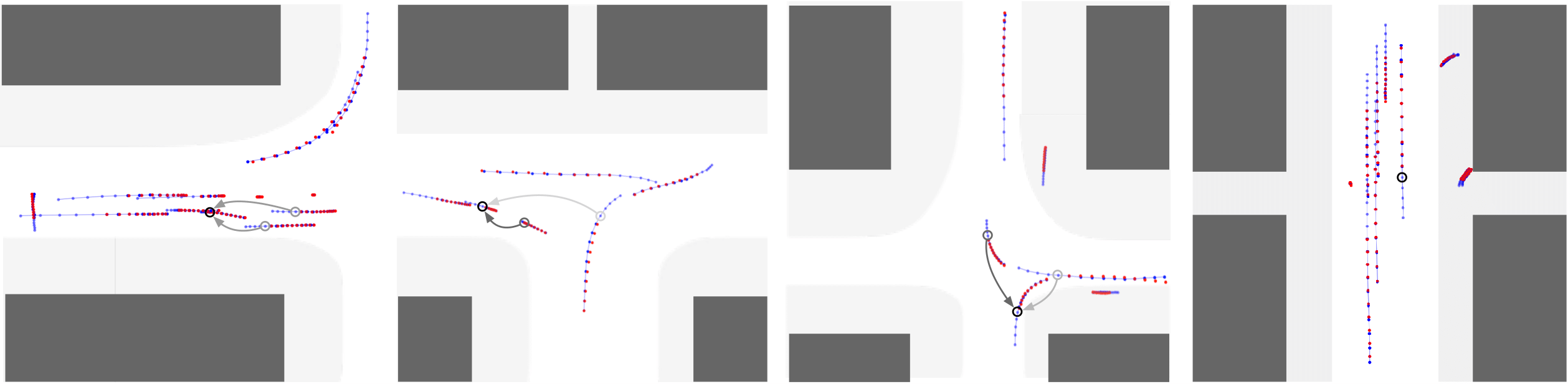
| The visualization of testing cases in the nuScenes dataset: The light blue dots are history observations, dark blue dots are ground truth, and red dots are predictions with the minimum ADE. The black circles indicate the target agent and gray arrows indicate hybrid attention. The targets only attend to the agents with arrows selected by hard attention and darker colors imply larger weights. There is no arrow in the last case, which implies that the model infers that the target is not influenced by any agent in the scene at current time. | ||
|
||
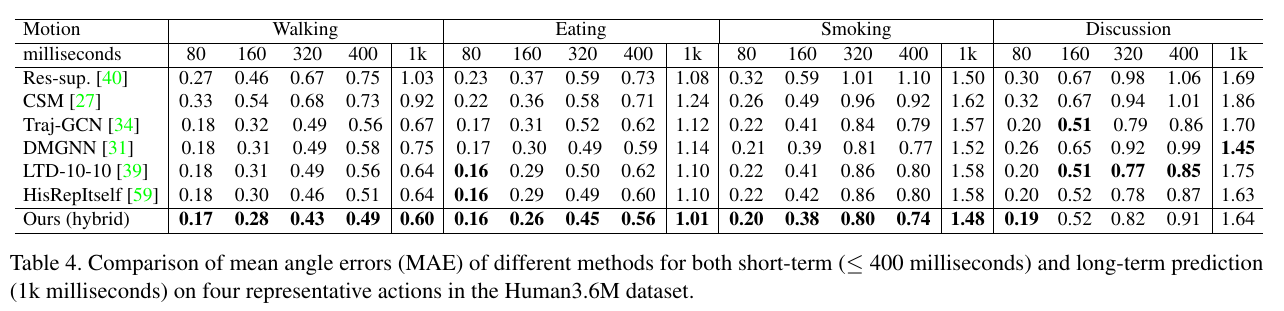
| Quantitive results on the Human3.6M dataset: Among the baselines, HisRepItself yields the previous state-of-the-art performance, which also serves as an ablation model with only soft attention on the motion history. In general, the results show that Ours (hybrid) achieves the best performance both in average and for most actions in terms of both short-term and long-term forecasting accuracy. In particular, Ours (hybrid) outperforms HisRepItself in average, indicating the additional benefits brought by the hard attention mechanism. Please refer to the paper for more details. | ||

|
||
| The visualization of human skeleton motion forecasting of four typical actions with hybrid attention maps: The black skeletons at the bottom are the latest observation sequences which are used to calculate current attention weights. The purple-green skeletons are the prediction hypotheses of our method. The blue-red skeletons are the ground truth. In our experimental setting, for each case there are 31 available history motion segments with a length of 10 frames for the RL hard attention module to select and the soft attention is only applied to the selected segments. In the hybrid attention maps, darker colors indicate larger attention weights. White color means the corresponding motion segment is not selected as key information. |
||
Acknowledgements |